正则表达式非常有用,查找、匹配、处理字符串、替换和转换字符串,输入输出等。而且各种语言都支持,例如.NET正则库,JDK正则包, Perl, JavaScript等各种脚本语言都支持正则表达式。下面整理一些常用的正则表达式。
1. 匹配组
常用的组匹配:(实用)
| 匹配exp并且捕获到一个自动命名的组 |
| 匹配exp并且捕获到组’name’ |
(?=exp) | exp出现在声明右侧,但exp不作为匹配括号中的模式必须出现在声明右侧,但不作为匹配的一部分 ,例如:输入: public keywod string "abc"; 正则:\w+(?=ing),返回“str”,意思为:匹配以ing结束的单词,但ing不作为返回 |
(?<=exp) | exp出现在声明左侧,但exp不作为匹配括号中的模式必须出现在声明左侧,但不作为匹配的一部分 ,例如:输入: public remember string "abc"; 正则:(?<=re)\w+,返回“member”,意思为:匹配以re开头的单词,但re不作为返回 |
| exp不出现在声明右侧,但exp不作为匹配括号中的模式必须不出现在声明右侧 ,例如:输入: remember aqa bqu "abc"; 正则:\w*q(?!u)\w*,返回“aqa”,意思为:匹配带q后面不是跟随u的单词 |
| exp不出现在声明左侧,但exp不作为匹配 |
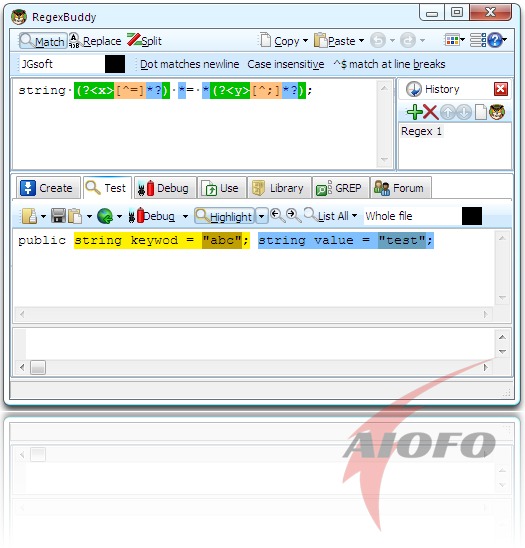
输入:public string keywod = "abc"; string value = "test";
目的:匹配 关键字="",例如获得关键字keyword,value;获得等于的值abc和test
表达式:string (?[^=]*?) *= *(?[^;]*?);
代码:
private void ParseKeywords(string input)
{
System.Text.RegularExpressions.MatchCollection mc =
System.Text.RegularExpressions.Regex.Matches(input, @"string (?[^=]*?) *= *(?[^;]*?);");
if (mc != null && mc.Count > 0)
{
foreach (System.Text.RegularExpressions.Match m in mc)
{
string keyword = m.Groups["x"].Value;
string value = m.Groups["y"].Value;
}
}
}
截图:
2. 匹配并替换
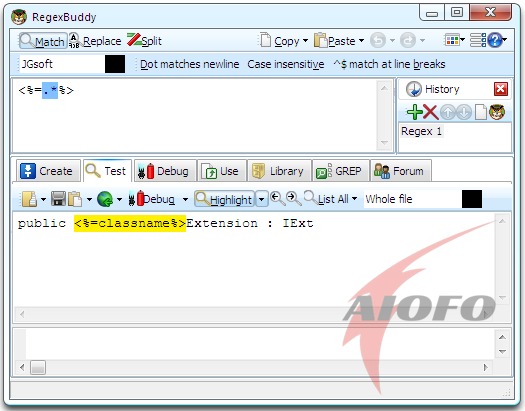
输入:public <%=classname%>Extension : IExt
目的:匹配 <%= %>中间的classname并替换
表达式:<%=.*%>
代码:
private string Replace(string input)
{
return Regex.Replace(input, @"<%=.*%>", new MatchEvaluator(RefineCodeTag), RegexOptions.Singleline);
}
string RefineCodeTag(Match m)
{
string x = m.ToString();
x = Regex.Replace(x, "<%=", ""); x = Regex.Replace(x, "%>", "");
return x.Trim() + ",";
}截图:
正则表达式选项RegexOptions:
ExplicitCapture | n | 只有定义了命名或编号的组才捕获 |
| IgnoreCase | i | 不区分大小写 |
| IgnorePatternWhitespace | x | 消除模式中的非转义空白并启用由 # 标记的注释。 |
| MultiLine | m | 多行模式,其原理是修改了^和$的含义 |
| SingleLine | s | 单行模式,和MultiLine相对应 |
正则表达式替换的其他功能:
| $number | 把匹配的第number组替换成替换表达式 这段代码返回的是 “01 012 03 05” 就是说,对组一的每个匹配结果都用"0$1"这个表达式来替换,"0$1"中"$1"由组1匹配的结果代入 public static void Main()
{
string s = "1 12 3 5";
s = Regex.Replace(s,@"(\d+)(?#这个是注释)","0$1",RegexOptions.Compiled|RegexOptions.IgnoreCase);
Console.WriteLine(s);
Console.ReadLine();
} |
${name} | 把匹配的组名为"name"的组替换成表达式, 上例的Regex expression改成@"(?\d+)(?#这个是注释)"后面的替换式改为"0${name}"结果是一样的 |
$$ | 做$的转义符,如上例表达式改成@"(?\d+)(?#这个是注释)"和"$$${name}",则结果为"$1 $12 $3 $5" |
| $& | 替换整个匹配 |
| $` | 替换匹配前的字符 |
| $' | 替换匹配后的字符 |
| $+ | 替换最后匹配的组 |
| $_ | 替换整个字符串 |
3. 匹配URL中文件名
输入:http://www.w3cschool.cn
目的:从URL地址中提取文件名
表达式:s=s.replace(/(.*\/){0,}([^\.]+).*/ig,"$2") ;
代码:
string s = "http://www.w3cschool.cn";
s = s.replace(/(.*\/){0,}([^\.]+).*/ig, "$2") ;
上一篇:正则表达式之空格
下一篇:正则表达式之任意字符